DINI-nestor-WS4: Unterschied zwischen den Versionen
| Zeile 145: | Zeile 145: | ||
Der 4. Workshop der DINI/nestor AG Forschungsdaten fand am 17.11.2015 an der Universität Dusiburg-Essen, Standort Essen statt und behandelte das Thema „Auswahl und Bewertung von Forschungsdaten“. | Der 4. Workshop der DINI/nestor AG Forschungsdaten fand am 17.11.2015 an der Universität Dusiburg-Essen, Standort Essen statt und behandelte das Thema „Auswahl und Bewertung von Forschungsdaten“. | ||
In einem ersten Block wurden neben einem einführenden Vortrag von Jens Ludwig zwei Praxisbeispiele aus dem Leibniz Institut für Sozialwissenschaften (GESIS) und der Deutschen Nationalbibliothek (DNB) vorgestellt. Jens Ludwig argumentierte, dass die Fragen, ob man auf alles aufbewahren kann und soll und wer dies entscheiden solle, weniger wichtig sein als die konkrete Gestaltung des Auswahlprozesses, für den er einen schematischen Entwurf vorstellte. Im Vortrag von Natascha Schuhmann wurde vorgestellt, welche Mindestanforderungen Gesis an Forschungsdaten stellt und wie das Nachnutzungspotenzial und Archivierungslevel bestimmt wird. Sabine Schrimpf stellte vor, dass die DNB aus ihrem gesetzlichen Auftrag die Aufbewahrungspflicht für diejenigen Forschungsdaten ableitet, die Teil von Publikationen sind. Anschließend berichtet Prof. Dr. Christian Keitel vom Landesarchiv Baden-Württemberg über die Praktiken im Umgang mit Forschungsdaten innerhalb des Archivwesens. Zentrale Unterscheidungen sind dabei der Primärwert - der Zweck für den die Unterlagen ursprünglich erstellt wurden - und der Sekundärwert - wonach die Nutzer im Archiv suchen. Das eine Bewertung stattfinden müsse, sei unzweifelhaft, denn eine Nicht-Bewertung sei eine Bewertung durch den Zufall. Das Archivwesen hat eine Reihe von unterschiedlichen Bewertungsmodellen und -verfahren je nach Unterlagentyp entwickelt, die von Herrn Keitel vorgestellt wurden. | In einem ersten Block wurden neben einem einführenden Vortrag von Jens Ludwig zwei Praxisbeispiele aus dem Leibniz Institut für Sozialwissenschaften (GESIS) und der Deutschen Nationalbibliothek (DNB) vorgestellt. Jens Ludwig argumentierte, dass die Fragen, ob man auf alles aufbewahren kann und soll und wer dies entscheiden solle, weniger wichtig sein als die konkrete Gestaltung des Auswahlprozesses, für den er einen schematischen Entwurf vorstellte. Im Vortrag von Natascha Schuhmann wurde vorgestellt, welche Mindestanforderungen Gesis an Forschungsdaten stellt und wie das Nachnutzungspotenzial und Archivierungslevel bestimmt wird. Sabine Schrimpf stellte vor, dass die DNB aus ihrem gesetzlichen Auftrag die Aufbewahrungspflicht für diejenigen Forschungsdaten ableitet, die Teil von Publikationen sind. Anschließend berichtet Prof. Dr. Christian Keitel vom Landesarchiv Baden-Württemberg über die Praktiken im Umgang mit Forschungsdaten innerhalb des Archivwesens. Zentrale Unterscheidungen sind dabei der Primärwert - der Zweck für den die Unterlagen ursprünglich erstellt wurden - und der Sekundärwert - wonach die Nutzer im Archiv suchen. Das eine Bewertung stattfinden müsse, sei unzweifelhaft, denn eine Nicht-Bewertung sei eine Bewertung durch den Zufall. Das Archivwesen hat eine Reihe von unterschiedlichen Bewertungsmodellen und -verfahren je nach Unterlagentyp entwickelt, die von Herrn Keitel vorgestellt wurden. | ||
In einem zweiten Vortragsblock berichtete Kerstin Helbig von der HU Berlin über Kriterien zur Auswahl und Bewertung von Forschungsdaten die innerhalb von Schulungen oder Beratungsgesprächen thematisiert werden. Zuletzt berichteten Paolo Budroni und Barbara Sánchez Solís von der Universität Wien zu den Umfrageergebnissen der österreichweiten Befragung zum Umgang mit Forschungsdaten im Rahmen des Projektes "[ | In einem zweiten Vortragsblock berichtete Kerstin Helbig von der HU Berlin über Kriterien zur Auswahl und Bewertung von Forschungsdaten die innerhalb von Schulungen oder Beratungsgesprächen thematisiert werden. Zuletzt berichteten Paolo Budroni und Barbara Sánchez Solís von der Universität Wien zu den Umfrageergebnissen der österreichweiten Befragung zum Umgang mit Forschungsdaten im Rahmen des Projektes "[http://www.e-infrastructures.at/ e-infrastructures Austria]". | ||
Im dritten Teil des Workshops wurden vier parallele Breakout-Sessions angeboten. In der ersten Session wurde das Kategorienschema des Verbundes Forschungsdaten Bildung vorgestellt und diskutiert. Die zweite Session beschäftigte sich praxisnah mit verschiedenen Beispielen und versuchte diese anhand verschiedener Kriterien zu bewerten. In der dritten Session wurden die verschiedenen Stakeholder und ihre Rollen und Interessen im Auswahlprozess betrachtet und diskutiert. In der letzten Session wurde ausprobiert, ob ein allgemeiner Auswahlprozess konstruiert werden kann. | Im dritten Teil des Workshops wurden vier parallele Breakout-Sessions angeboten. In der ersten Session wurde das Kategorienschema des Verbundes Forschungsdaten Bildung vorgestellt und diskutiert. Die zweite Session beschäftigte sich praxisnah mit verschiedenen Beispielen und versuchte diese anhand verschiedener Kriterien zu bewerten. In der dritten Session wurden die verschiedenen Stakeholder und ihre Rollen und Interessen im Auswahlprozess betrachtet und diskutiert. In der letzten Session wurde ausprobiert, ob ein allgemeiner Auswahlprozess konstruiert werden kann. | ||
In der abschließenden Diskussion wurde über die parallele Existenz von Fachrepositorien neben institutionellen Repositorien und den unterschiedlichen Auswahlprozessen dieser Repositorien diskutiert. Es wurde deutlich, dass grundsätzlich beide Arten benötigt werden, eine stärkere Kooperation jedoch denkbar und wünschenswert wäre. Im Anschluss wurde darüber diskutiert, ob es möglich ist, als Output des Workshops einen generischen Leitfaden als eine Art Werkzeugkasten für den Auswahlprozess zu erstellen. Dieses Aufgabe soll nach dem Workshop von einer kleinen Freiwilligengruppe aus dem Kreis der Arbeitsgruppe weiterbearbeitet werden. Zuletzt wurde noch über mögliche weitere Workshop-Themen diskutiert. Neben dem Thema Fortbildungsangebote auch bereichsübergreifend zu konzipieren bzw. anzubieten wurde auch das Thema Rahmenbedingungen für Vertragsgestaltung genannt. | In der abschließenden Diskussion wurde über die parallele Existenz von Fachrepositorien neben institutionellen Repositorien und den unterschiedlichen Auswahlprozessen dieser Repositorien diskutiert. Es wurde deutlich, dass grundsätzlich beide Arten benötigt werden, eine stärkere Kooperation jedoch denkbar und wünschenswert wäre. Im Anschluss wurde darüber diskutiert, ob es möglich ist, als Output des Workshops einen generischen Leitfaden als eine Art Werkzeugkasten für den Auswahlprozess zu erstellen. Dieses Aufgabe soll nach dem Workshop von einer kleinen Freiwilligengruppe aus dem Kreis der Arbeitsgruppe weiterbearbeitet werden. Zuletzt wurde noch über mögliche weitere Workshop-Themen diskutiert. Neben dem Thema Fortbildungsangebote auch bereichsübergreifend zu konzipieren bzw. anzubieten wurde auch das Thema Rahmenbedingungen für Vertragsgestaltung genannt. | ||
Version vom 19. Januar 2016, 18:42 Uhr
4. DINI/nestor-Workshop "Forschungsdaten auswählen und bewerten"
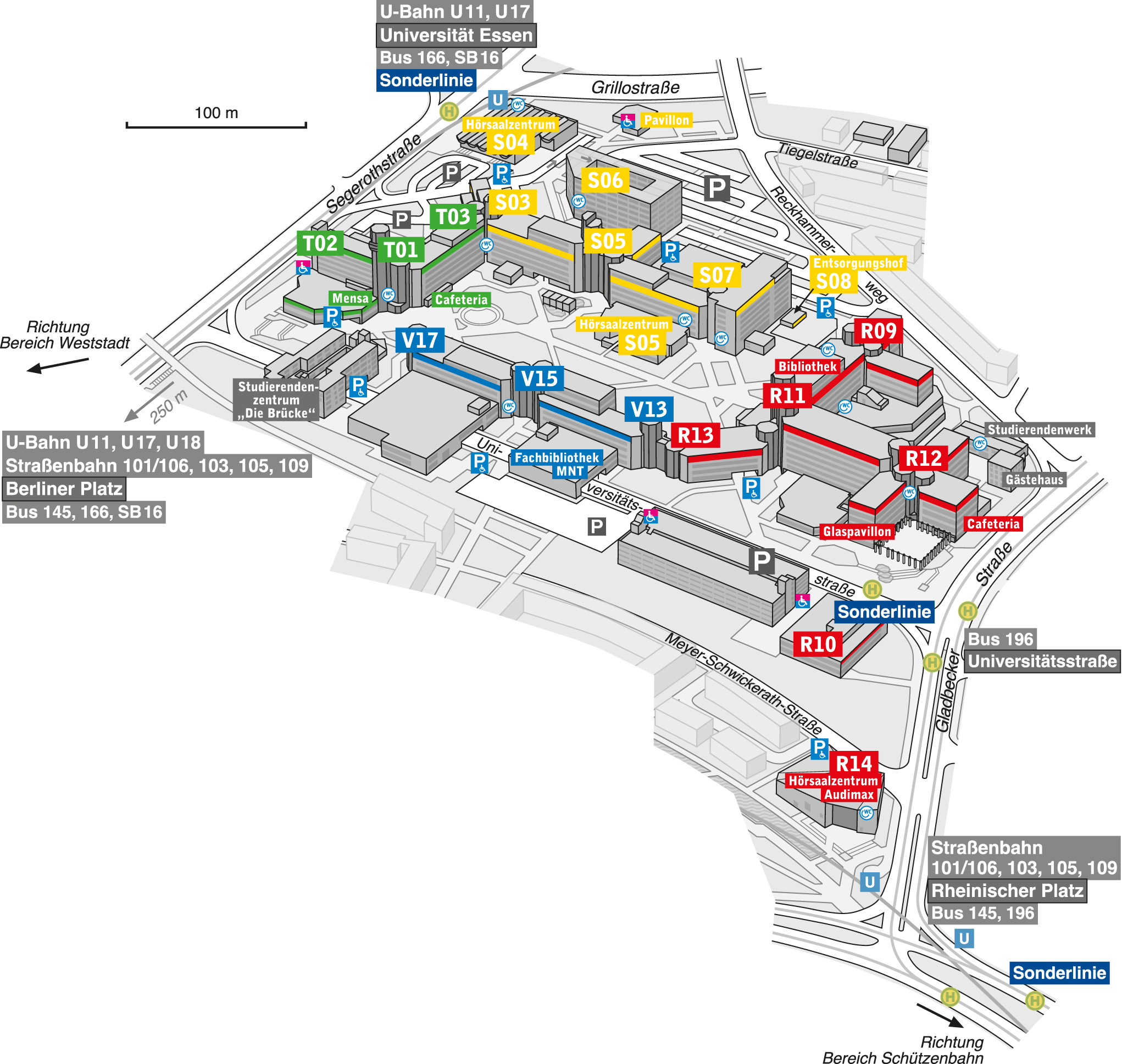
Ort: Universität Duisburg-Essen, Glaspavillon (R12 S00 H12), Campus Essen, Universitätsstr. 12, 45141 Essen
Termin: 17. November 2015 , 10:00-16:00 Uhr
{kind=link}
Ankündigung
Unsere Fähigkeit Forschungsdaten zu erzeugen übersteigt unsere Fähigkeit Forschungsdaten aufzubewahren". Diese populäre Position wird ganz unterschiedlich verstanden und diskutiert: Ist das Datenvolumen zu hoch für die derzeitigen Speichertechnologien oder werden die Speicherkosten einfach nicht sinnvoll umgelegt? Sind Speichertechnologien überhaupt ein Problem? Ist es zu aufwändig Forschungsdaten für die Nachnutzung und Archivierung ausreichend zu beschreiben oder fehlen nur die Werkzeuge? Hinter diesen und anderen diskutierten Fragen gibt es aber eine sehr grundlegende Frage, die bemerkenswerterweise fast nie offen thematisiert wird: Wie wird entschieden, welche Forschungsdaten in welcher Form aufbewahrt werden und welche nicht? Wer entscheidet letztlich über Auswahl und Archivierung? VertreterInnen von Infrastruktureinrichtungen, die diese Frage wegen knapper Ressourcen stellen müssten, trauen sich nicht, sie in Gegenwart von WissenschaftlerInnen zu stellen, weil sie von diesen oft als fachliche Anmaßung missverstanden wird. Personen, die Forschungsdaten-Repositorien aufbauen, scheuen die Frage, weil sie überhaupt erst einmal Forschungsdaten bekommen und eine Akzeptanz des Angebots etablieren müssen. Wissenschaftler wiederum wünschen sich möglicherweise klare Kritierien und Vorgaben.
Die DINI-nestor-AG Forschungsdaten will die Frage der Auswahl und Bewertung von Forschungsdaten in einem Workshop am 17.11.2015 an der UB Duisburg-Essen behandeln. Der Workshop wird sicherlich nicht abschließende Klärungen in diesem unterbeleuchteten Themenfeld erreichen oder klare Handlungsempfehlungen liefern, sondern will zunächst die zu diskutierenden Faktoren herauszuarbeiten. Wir möchten deshalb die interessierte Community auffordern, nicht nur Themen für Vorträge sondern auch für Breakout-Sessions beizutragen. Vorträge können Erfahrungsberichte aus der Praxis, aber auch Analysen und ausgearbeitete Positionen vorstellen. In den Breakout-Sessions soll TeilnehmerInnen die Möglichkeit gegeben werden, konstruktiv und vertieft an einzelnen Fragestellungen zu arbeiten.
Z.B. können Vorträge und Breakout-Sessions die Fragen behandeln:
- Aus welchen Gründen erfolgt die Datenauswahl oder aus welchen Gründen wird auf eine Selektion verzichtet? Wie beeinflussen ökonomische, technische und andere Faktoren die Auswahl?
- Wie laufen Auswahlprozesse ab? Was sind etablierte Auswahlprozesse in unterschiedlichen Fachdisziplinen oder in anderen Fachcommunities, die sich nicht mit Forschungsdaten beschäftigen? Was sind übertragbare Erkenntnisse?
- Welche Akteure oder Gremien sind an der Planung und an der Durchführung der Auswahlprozesse beteiligt?
- Wie schätzen Institutionen das Datenwachstum ab und wie planen sie darauf aufbauend ihre Service-Angebote und Investitionen?
- Was sind Auswahlkriterien für Forschungsdaten und in welche Kategorien werden sie eingeteilt?
- Werden Forschungsdaten für unterschiedliche Dienstleistungsarten ausgewählt oder in unterschiedliche Kategorien eingeteilt? Gibt es z.B. Kriterien für eine "Gold", "Silber", "Bronze"-Aufbewahrung von Forschungsdaten?
Anmeldung
Die Teilnehmerzahl ist auf 80 begrenzt und die Teilnahmegebühr beträgt 15 €. Wir bitten um Ihr Verständnis.
Die Anmeldung ist über die DINI-Webseite möglich.
Programm
| 9:00 bis 10:00 Uhr | Registrierung |
| 10:00 bis 10:15 Uhr | Begrüßung durch die DINI/nestor-AG Forschungsdaten und UB Duisburg-Essen Janna Neumann (TIB Hannover) und Ania Lopez (UB Duisburg-Essen) |
| 10:15 bis 11:30 Uhr | Vortragsblock 1, Moderation: Janna Neumann |
| Forschungsdaten auswählen: Ziele und Prozesse Jens Ludwig (Staatsbibliothek zu Berlin) | |
| Auswahl von Forschungsdaten am Beispiel GESIS Datenarchiv Natascha Schumann, Reiner Mauer (GESIS) | |
| Umgang der Deutschen Nationalbibliothek mit Forschungsdaten Sabine Schrimpf (Deutsche Nationalbibliothek) | |
| 11:30 bis 12:00 Uhr | Keynote: Auswahl und Bewertung digitaler Forschungsdaten aus archivwissenschaftlicher Perspektive Christian Keitel (Landesarchiv Baden-Württemberg) |
| 12:00 bis 13:00 Uhr | Mittagspause |
| 13:00 bis 14:00 Uhr | Vortragsblock 2, Moderation: Jens Ludwig |
| Auswahl und Bewertung von Forschungsdaten aus Sicht der Beratung und Schulung Kerstin Helbig (HU Berlin) | |
| Nationale Befragung zu Forschungsdatenmanagement – Erfahrung und Bericht aller österreichischen Universitäten Paolo Budroni, Barbara Sánchez Solís (Universität Wien) | |
| 14:00 bis 15:00 Uhr | Breakout-Sessions |
| Session 1: Schritt für Schritt im Auswahlprozess von Forschungsdaten – Das Kategorienschema des Verbundes Forschungsdaten Bildung Moderatoren: Maike Porzelt, Thomas Schwager (DIPF) | |
| Session 2: Praktische Übung zum Auswählen und Bewerten von Forschungsdaten Moderator: Dominik Schmitz (RWTH Aachen) | |
| Session 3: Stakeholder im Auswahl- und Bewertungsprozess Moderatorin: Janna Neumann (TIB Hannover) | |
| Session 4: Wir konstruieren einen Auswahlprozess Moderator: Jens Ludwig (Staatsbibliothek zu Berlin) | |
| 15:00 bis 15:15 Uhr | Kaffeepause |
| 15:15 bis 16:00 Uhr | Abschlussdiskussion und Berichte aus den Breakout-Sessions |
Abstracts und Präsentationsfolien
Forschungsdaten auswählen: Ziele und Prozesse
Jens Ludwig (Staatsbibliothek zu Berlin)
Unter "Forschungsdatenmanagement" werden ganz verschiedene Aktivitäten verstanden: Fragen der Nachnutzung, der Sicherung der Guten Wissenschaftlichen Praxis und der Verbesserung der Forschung spielen in diesen Begriff hinein. Welches Ziel mit Forschungsdatenmanagement verfolgt wird, bestimmt wesentlich, wie der Auswahl- und Bewertungsprozess aussehen muss. Dieser Vortrag wird einige Fragen formulieren, Unterscheidungen anbieten und einen formalen Auswahl- und Bewertungsprozess vorstellen, um einen gemeinsamen Bezugs- und Reibungspunkt für die praktischen Konzepte und Erfahrungsberichte im weiteren Verlauf des Workshops anzubieten.
Auswahl von Forschungsdaten am Beispiel GESIS Datenarchiv
Natascha Schumann, Reiner Mauer (GESIS)
Eine der zentralen Aufgaben von GESIS – Leibniz-Institut für Sozialwissenschaften ist es, Forschungsdaten der empirischen Sozialforschung – und zwar vorrangig solche aus nationalen und international vergleichenden Umfragen – langfristig zu archivieren und zugänglich zu machen. In einer Collection Policy werden die Schwerpunkte der Sammlung ausführlicher definiert. Zudem ist festgelegt, welche Informationen zusätzlich zu den eigentlichen Daten mitgeliefert werden müssen, damit eine langfristige Sicherung und Nutzung der Daten gewährleistet werden kann.
Da es unterschiedliche Anforderungen an die Archivierung von sozialwissenschaftlichen Forschungsdaten gibt, bspw. im Hinblick auf die Dauer der Archivierung, Qualität und Umfang der Dokumentation oder die zu erwartende Nachnutzung, werden eingehende Daten auf der Basis von Kriterien mit einem differenzierten Leistungsspektrum bearbeitet und archiviert. Zunächst müssen Daten bestimmte formale Mindestanforderungen erfüllen, um in das Archiv aufgenommen zu werden. Falls eine Studie diese Minimalkriterien nicht erfüllt, wird sie abgelehnt oder gegebenenfalls an eine andere Daten haltende Institution verwiesen. Im nächsten Schritt findet eine Einschätzung des (Nach-)Nutzungspotenzials auf der Grundlage verschiedener formaler, technischer, methodischer und inhaltlicher Kriterien statt. Auf der Grundlage dieser Einschätzung wird über das nachfolgende Bearbeitungs- bzw. Archivierungsniveau entschieden. Derzeit differenziert das Datenarchiv drei verschiedene Archivierungsniveaus, die zukünftig zu zwei Leistungsstufen zusammengefasst werden (Standardarchivierung und Added-Value-Archivierung).
Die Archivierungsstufen unterscheiden sich vor allem hinsichtlich des Ressourcenaufwands seitens des Archivs bei der Erschließung, Qualitätssicherung, Aufbereitung und Dokumentation der Daten. Im Bereich der Standardarchivierung wird eine Bitstream Preservation für zehn Jahre zugesichert (wenngleich längere Vorhaltezeiten nicht ausgeschlossen sind), wohingegen für Daten, die von GESIS im Rahmen der Added-Value-Archivierung kuratiert werden, die langfristige Verfügbarkeit und Nutzbarkeit garantiert wird.
Der Beitrag stellt die entsprechenden Kriterien vor, die über eine Aufnahme von Daten und die jeweiligen Archivierungsniveaus entscheiden, erläutert Unterschiede der Leistungsniveaus und geht auf die Herausforderungen ein, die vor allem in der Definition transparenter Regeln sowie ihrer regelmäßigen Überprüfung und Anpassung liegen.
Umgang der Deutschen Nationalbibliothek mit Forschungsdaten
Sabine Schrimpf (Deutsche Nationalbibliothek)
Die Deutsche Nationalbibliothek hat den Auftrag, lückenlos alle deutschen und deutschsprachigen Publikationen ab 1913 zu sammeln, dauerhaft zu archivieren und der Öffentlichkeit zur Verfügung zu stellen. Der 2006 erweiterte Auftrag, auch „Medienwerke in unkörperlicher Form als Darstellung in öffentlichen Netzen“ zu sammeln, ist so weit formuliert, dass er angesichts der damit umfassten Masse an Daten einer exakteren Auslegung (in der Pflichtablieferungsverordnung) bedarf. Während diese Auslegung für digital veröffentlichte Forschungsdaten in der ersten Version der Pflichtablieferungsverordnung von 2008 noch unterblieb, wurde in der aktualisierten Fassung von 2014 klargestellt, dass selbstständig veröffentlichte Primär-, Forschungs- und Rohdaten von der Sammelpflicht ausgeschlossen sind. Forschungsdaten werden daher nur in die Sammlung der DNB aufgenommen, wenn sie als Bestandteil von Publikationen abgeliefert werden. So wird die Einheit von Publikation und der ihr unmittelbar zugrundeliegenden Daten gewahrt, eine künftige Überprüfung der Ergebnisse anhand der Originaldaten grundsätzlich ermöglicht.
In dem Vortrag soll diese Festlegung anhand des ODE-Typologiemodells erläutert werden. Die derzeit gängige Praxis an der DNB soll anhand einiger Beispiele verdeutlicht und auch die Grenzen des DNB-Ansatzes nicht verschwiegen werden: Die Sicherung der dauerhaften Les- und Interpretierbarkeit der Forschungsdaten übersteigt die Mittel und das Know-How der DNB und ist nur im Verbund mit den jeweiligen Fachdisziplinen möglich.
Auswahl und Bewertung von Forschungsdaten aus Sicht der Beratung und Schulung
Kerstin Helbig (HU Berlin)
Die Auswahl und Bewertung von Forschungsdaten stellt viele Wissenschaftler vor eine große Herausforderung. Die eigene Arbeit objektiv zu beurteilen und relevante Dateien zur Archivierung auszuwählen ist nicht einfach. Wie berät man einen Wissenschaftler bei der Wahl geeigneter Forschungsdaten zur Archivierung? Der Vortrag befasst sich mit Kriterien zur Auswahl von Forschungsdaten, die in der Beratung und Schulung zum Forschungsdatenmanagement vermittelt werden. Ebenso wird dargestellt, wer im Entscheidungsprozess um Auswahl und Bewertung von Forschungsdaten welche Rolle einnimmt. Verdeutlicht wird die Thematik anhand exemplarischer Praxisbeispiele aus der Forschungsdatenmanagementberatung der Humboldt-Universität zu Berlin.
Nationale Befragung zu Forschungsdatenmanagement – Erfahrung und Bericht aller österreichischen Universitäten
Paolo Budroni, Barbara Sánchez Solís (Universität Wien)
Anfang 2015 erging an das wissenschaftliche und künstlerisch-wissenschaftliche Personal aller 21 Universitäten sowie drei außeruniversitärer Forschungseinrichtungen in Österreich der Aufruf, sich an einer österreichweiten Umfrage zu Forschungsdaten zu beteiligen. Die Befragung erfolgte im Rahmen des Projekts e-Infrastructures Austria (www.e-infrastructures.at).
Die Teilnehmenden wurden unter anderem zu folgenden Themenbereichen befragt: Datentypen und Formate, Beschreibung von Daten, Volumen, Umgang mit Datenarchivierung, ethische und rechtliche Aspekte, Zugänglichkeit und Nachnutzung sowie Infrastruktur und Services. Die Erkenntnisse bilden die Basis für eine konsekutive Optimierung der Infrastruktur und mögliche zentrale Serviceangebote.
Erstmals wird der Status Quo flächendeckend und quer durch alle Disziplinen repräsentativ abgebildet. Die Ergebnisse bilden die Grundlage für die Entwicklung möglicher Strategien und/oder Policies für den Umgang mit Forschungsdaten für alle beteiligten Einrichtungen. Die daraus resultierenden Archivierungsstrategien klären Fragen zur Auswahl und Aufbewahrung der Daten und die dahinterliegenden Entscheidungsprozesse. Das hilft, Rollen, Kompetenzen, Verantwortungen und Ressourcenaufteilung unter den beteiligten Stakeholdern zu definieren.
Session 1: Schritt für Schritt im Auswahlprozess von Forschungsdaten – Das Kategorienschema des Verbundes Forschungsdaten Bildung
Moderatoren: Maike Porzelt, Thomas Schwager (DIPF)
In dem vom BMBF geförderten Pilotprojekt „„Sicherung und Nachnutzung der Forschungsdaten des Rahmenprogramms zur Förderung der empirischen Bildungsforschung“ stehen die drei Verbundpartner GESIS, IQB und DIPF in großem Umfang vor der Aufgabe, die Daten von bis zu 300 Forschungsprojekten aus genanntem Rahmenprogramm zu sichern und einen ausgewählten Teil aufzubereiten und bereit zu stellen. Auf Grund der heterogenen Ausrichtung des Rahmenprogramms mit 15 Forschungsschwerpunkten und zahlreicher zu dokumentierenden Mixed-Methods-Studien mussten die drei Partnerinstitute einen Weg finden, unterschiedlichste Daten von nicht standardisiertem qualitativem Content inklusive Videomaterial im Terabyte-Bereich bis hin zu rein quantitativem Datenmaterial wie Umfragedaten und Kompetenz- und Leistungsmessungsdaten in klarer Zuständigkeit geeigneten Eingangsprüf- und Auswahlmechanismen zu unterziehen und somit Kriterien für die Aufbereitung ausgesuchter Datenkollektionen über die bloße Sicherung hinaus zu schaffen. Hierzu wurden technisch-formale und inhaltliche Checklisten zur Qualitätskontrolle entwickelt, aber auch vor allem ein Kategorienschema konstruiert, das transparent die Entscheidung pro oder contra Archivierung und Aufbereitung der Daten nachvollziehbar werden lässt. Im Rahmen dieses Beitrags soll gezeigt werden, wie diese Prüf- und Kontrollmechanismen in der Praxis zum Tragen kommen, wie das Kategorienschema bei der Entscheidungsfindung und der Eruierung des Nachnutzungspotenzials eine wichtige Rolle einnimmt und welche Gefahren und Chancen daraus resultieren.
Session 2: Praktische Übung zum Auswählen und Bewerten von Forschungsdaten
Moderator: Dominik Schmitz (RWTH Aachen)
Im Rahmen der Breakout-Session werden in Kleingruppen konkrete Forschungsdatenbeispiele besprochen und "entschieden": Ja, die Forschungsdaten sollen aufbewahrt werden oder Nein, das ist nicht erforderlich. In beiden Fällen ist die jeweilige Entscheidung aufgrund von Informationen in der Beschreibung zu begründen. Sie wird im Anschluss der "Expertenmeinung" des Datenlieferanten gegenübergestellt.
Die konkreten, der Praxis entnommenen Forschungsdatenbeispiele werden im Vorfeld zum Workshop gesammelt und aufbereitet. Jeder Teilnehmer des Workshops ist aufgefordert, jeweils ein aufzubewahrendes bzw. ein nicht-aufzubewahrendes Forschungsdaten-Beispiel einzureichen. Da im Rahmen der Session wenig Zeit zum Sichten der eigentlichen Forschungsdaten bleiben würde, genügt eine kurze Prosa-Beschreibung (ca. eine Seite), die die wesentlichen Informationen enthält insbesondere auch die Informationen die aus Sicht des Datenlieferanten entscheidend für bzw. gegen eine Aufbewahrung sprechen. Die Beschreibung sollte möglichst neutral formuliert werden, um den Session-Teilnehmer keine zu deutlichen Anhaltspunkte zu geben, ob der Datenlieferant die Daten für aufbewahrenswert hält oder nicht (nötigenfalls behalten sich die Session-Organisatoren die Möglichkeit vor, die Beschreibung entsprechend dieser Vorgabe zu verändern).
Die Datenbeschreibungen (RichText-Format) bitte bis Sonntag, 08.11.2015 per Mail an d.schmitz@ub.rwth-aachen.de.
Session 3: Stakeholder im Auswahl- und Bewertungsprozess
Moderatorin: Janna Neumann (TIB Hannover)
In dieser Session wird diskutiert und gesammelt, welche Gruppen an der Definition und Ausführung des Auswahl- und Bewertungsprozesses beteiligt sind oder beteiligt werden sollten. Denn es ist nicht immer klar, welche Interessen und Prioritäten beim Auswahl- und Bewertungsprozess existieren. Z.B. trifft der Leidensdruck, angesichts knapper Ressourcen mit großen Datenmengen umzugehen, unterschiedliche Vertreter der Infrastruktur und Wissenschaft in unterschiedlichem Maße. Und die Aufbewahrung und gewollte oder ungewollte qualitative Auszeichung bestimmter Forschungsdaten hat Konsequenz für Forscher und Forschungsrichtungen. Daher stellt sich die Frage: Wer definiert diese Prozesse und wie sollte eine Beteiligung der verschiedenen Stakeholder an der Gestaltung aussehen? Wann muss dies z.B. auf lokaler, auf nationaler oder auf fachlicher Ebene erfolgen oder wann kann es sogar eine individuelle Entscheidung sein? Was kann man praktisch Personen raten, die einen solchen Prozess anstoßen und gestalten wollen?
Session 4: Wir konstruieren einen Auswahlprozess
Moderator: Jens Ludwig (Staatsbibliothek zu Berlin)
Im Laufe des gesamten Workshop-Tages werden verschiedene Beispiele für Auswahlprozesse vorgestellt. Diese Session wird versuchen, die verschieden Beispiele und Überlegungen zusammenzuführen, und untersuchen, ob sich aus ihnen ein oder mehrere gemeinsame Kernprozesse konstruieren lassen. Was sind die Faktoren, die im konkreten Fall eine Anpassung dieser Prozesse beeinflussen? Kann man Institutionen oder Gruppen, die vor der Aufgabe stehen, einen Auswahl- und Bewertungsprozess zu gestalten, Vorlagen oder Anleitungen geben? Falls sich dies als sinnvoll oder möglich erweist, soll diskutiert werden, ob auf den Ergebnissen des Workshops basierend eine Empfehlung oder ein Leitfaden erarbeitet werden kann.
Protokoll
Der 4. Workshop der DINI/nestor AG Forschungsdaten fand am 17.11.2015 an der Universität Dusiburg-Essen, Standort Essen statt und behandelte das Thema „Auswahl und Bewertung von Forschungsdaten“. In einem ersten Block wurden neben einem einführenden Vortrag von Jens Ludwig zwei Praxisbeispiele aus dem Leibniz Institut für Sozialwissenschaften (GESIS) und der Deutschen Nationalbibliothek (DNB) vorgestellt. Jens Ludwig argumentierte, dass die Fragen, ob man auf alles aufbewahren kann und soll und wer dies entscheiden solle, weniger wichtig sein als die konkrete Gestaltung des Auswahlprozesses, für den er einen schematischen Entwurf vorstellte. Im Vortrag von Natascha Schuhmann wurde vorgestellt, welche Mindestanforderungen Gesis an Forschungsdaten stellt und wie das Nachnutzungspotenzial und Archivierungslevel bestimmt wird. Sabine Schrimpf stellte vor, dass die DNB aus ihrem gesetzlichen Auftrag die Aufbewahrungspflicht für diejenigen Forschungsdaten ableitet, die Teil von Publikationen sind. Anschließend berichtet Prof. Dr. Christian Keitel vom Landesarchiv Baden-Württemberg über die Praktiken im Umgang mit Forschungsdaten innerhalb des Archivwesens. Zentrale Unterscheidungen sind dabei der Primärwert - der Zweck für den die Unterlagen ursprünglich erstellt wurden - und der Sekundärwert - wonach die Nutzer im Archiv suchen. Das eine Bewertung stattfinden müsse, sei unzweifelhaft, denn eine Nicht-Bewertung sei eine Bewertung durch den Zufall. Das Archivwesen hat eine Reihe von unterschiedlichen Bewertungsmodellen und -verfahren je nach Unterlagentyp entwickelt, die von Herrn Keitel vorgestellt wurden. In einem zweiten Vortragsblock berichtete Kerstin Helbig von der HU Berlin über Kriterien zur Auswahl und Bewertung von Forschungsdaten die innerhalb von Schulungen oder Beratungsgesprächen thematisiert werden. Zuletzt berichteten Paolo Budroni und Barbara Sánchez Solís von der Universität Wien zu den Umfrageergebnissen der österreichweiten Befragung zum Umgang mit Forschungsdaten im Rahmen des Projektes "e-infrastructures Austria". Im dritten Teil des Workshops wurden vier parallele Breakout-Sessions angeboten. In der ersten Session wurde das Kategorienschema des Verbundes Forschungsdaten Bildung vorgestellt und diskutiert. Die zweite Session beschäftigte sich praxisnah mit verschiedenen Beispielen und versuchte diese anhand verschiedener Kriterien zu bewerten. In der dritten Session wurden die verschiedenen Stakeholder und ihre Rollen und Interessen im Auswahlprozess betrachtet und diskutiert. In der letzten Session wurde ausprobiert, ob ein allgemeiner Auswahlprozess konstruiert werden kann. In der abschließenden Diskussion wurde über die parallele Existenz von Fachrepositorien neben institutionellen Repositorien und den unterschiedlichen Auswahlprozessen dieser Repositorien diskutiert. Es wurde deutlich, dass grundsätzlich beide Arten benötigt werden, eine stärkere Kooperation jedoch denkbar und wünschenswert wäre. Im Anschluss wurde darüber diskutiert, ob es möglich ist, als Output des Workshops einen generischen Leitfaden als eine Art Werkzeugkasten für den Auswahlprozess zu erstellen. Dieses Aufgabe soll nach dem Workshop von einer kleinen Freiwilligengruppe aus dem Kreis der Arbeitsgruppe weiterbearbeitet werden. Zuletzt wurde noch über mögliche weitere Workshop-Themen diskutiert. Neben dem Thema Fortbildungsangebote auch bereichsübergreifend zu konzipieren bzw. anzubieten wurde auch das Thema Rahmenbedingungen für Vertragsgestaltung genannt.
Zusammenfassung Breakout-Session 1 – "Schritt für Schritt im Auswahlprozess von Forschungsdaten – Das Kategorienschema des Verbundes Forschungsdaten Bildung" Die Breakout-Session 1 stellte den Auswahlprozess des Verbundes Forschungsdaten Bildung vor, in dem die Entscheidung für oder gegen die Aufbewahrung getroffen wird. Die vier Hauptkategorien zur Begründung der Auswahl sind inhaltliche Eignung, Nachnutzungspotenzial, technische Qualität und der dokumentarische Aufbereitungsaufwand und wurden mit den TeilnehmerInnen diskutiert.
Zusammenfassung Breakout-Session 2 – "Praktische Übung zum Auswählen und Bewerten von Forschungsdaten" In der zweiten Breakout-Session wurden fünf Forschungsdatenbeispiele vorgestellt und diskutiert, aus welchen Gründen sie aufbewahrt werden sollten oder nicht. Die Entscheidungen der Gruppe entsprachen in drei Fällen den Entscheidungen, die auch mit den Daten vertraute Experten im Vorfeld des Workshops getroffen hatten. Eine Feststellung der Breakout-Session war, dass eine Entscheidung ohne Unterstützung durch Ersteller oder Fachcommunity sehr unangenehm ist. Details zu der Session finden sich in der Ergebnispräsentation.
Zusammenfassung Breakout-Session 3 - "Stakeholder im Auswahl- und Bewertungsprozess" In der Breakout-Session 3 -Stakeholder im Auswahl und Bewertungsprozess wurde zunächst darüber diskutiert in wie weit der einzelne Wissenschaftler über die Relevanz der eigenen Daten entscheidet bzw. entscheiden kann. Bei der Betrachtung der einzelnen Stakeholder (Institutionen, Förderer, Fachcommunity, Verlage, Infrastrukturbetreiber, Projektpartner) wurde deutlich, dass der Auswahlprozess in der Regel durch einzelne oder mehrere Stakeholder mitbestimmt wird. Hier spielen neben Policies von Institutionen, Förderern oder Verlagen auch Kriterien der Infrastrukturbetreiber eine entscheidende Rolle. Nicht zuletzt aber wird der Auswahlprozess durch die Nachnutzung der Fachcommunity geprägt und ggf. auch angepasst. Im Zuge der Internationalisierung der Wissenschaft ist auch die multilinguale Aufbereitung von Daten ein ausschlaggebendes Kriterium für den Auswahlprozess.
Zusammenfassung Breakout-Session 4 - "Wir konstruieren einen Auswahlprozess" Die Breakout-Session diskutierte, wie ein Auswahlprozess für Forschungsdaten aussehen kann. Ein zentraler Diskussionspunkt war, dass vielfältige und unterschiedliche Auswahlkriterien notwendig sind, weil es auch unterschiedliche Arten der Nachnutzung und damit verbundene Service-Level gibt. So ist z.B. auch die Aufbewahrung negativer Ergebnisse wichtig, damit andere Forschungsvorhaben sie nicht wiederholen, auch wenn diese Daten nicht in das Muster der meist diskutierten Nachnutzungsfälle passen. Ein weiterer Diskussionspunkt war, dass es sinnvoll sein kann, die Auswahlverfahren anstelle der Kriterien in den Vordergrund zu stellen, wie z.B. ob die Erzeuger, ein Expertengremium oder Förderer über die Aufbewahrung entscheiden oder ob man formale Kriterien wie Datengröße oder messbare Nachfrage für die Entscheidung benutzen kann.